Big data — что это такое простыми словами Под термином «большие данные» буквально понимают огромный объем хранящейся на каком-либо носителе информации.
- Перспективы и тенденции развития Big data
- Облачные хранилища
- Использование Dark Data
- Искусственный интеллект и Deep Learning
- Blockchain
- Самообслуживание и снижение цен
- Большие данные в маркетинге и бизнесе
- Чем выгодно применение технологий больших данных в маркетинге и бизнесе?
- Примеры использования Big Data
- Проблемы Big Data
- Рынок технологий больших данных в России и мире
- Лучшие книги по Big Data
- «The Human Face of Big Data», Рик Смолан и Дженнифер Эрвитт
- «Introduction to Data Mining», Панг-Нинг Тан, Майкл Стейнбах и Випин Кумар
- «Python Machine Learning», Себастьян Рашка
- «Hadoop for Dummies», Дирк Дерус, Пол С. Зикопулос, Роман Б. Мельник
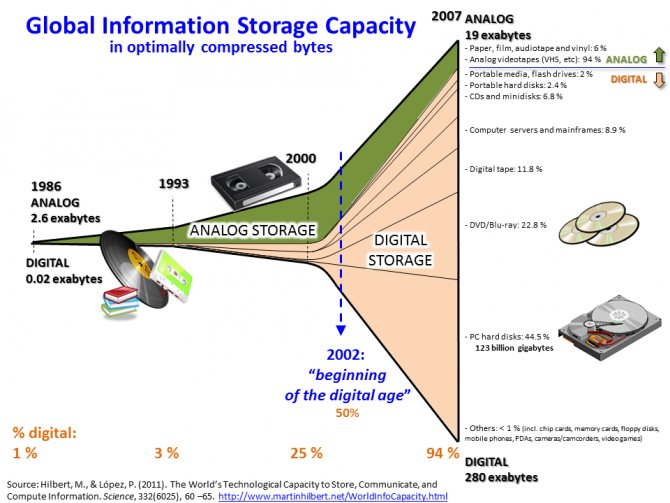
Причем данный объем настолько велик, что обрабатывать его с помощью привычных программных или аппаратных средств нецелесообразно, а в некоторых случаях и вовсе невозможно.
Big Data – это не только сами данные, но и технологии их обработки и использования, методы поиска необходимой информации в больших массивах. Проблема больших данных по-прежнему остается открытой и жизненно важной для любых систем, десятилетиями накапливающих самую разнообразную информацию.
С данным термином связывают выражение «Volume, Velocity, Variety» – принципы, на которых строится работа с большими данными. Это непосредственно объем информации, быстродействие ее обработки и разнообразие сведений, хранящихся в массиве. В последнее время к трем базовым принципам стали добавлять еще один – Value, что обозначает ценность информации. То есть, она должна быть полезной и нужной в теоретическом или практическом плане, что оправдывало бы затраты на ее хранение и обработку.
Что такое «большие данные»
Вопрос «что называть большими данными» довольно путаный. Даже в публикациях научных журналов описания расходятся. Где-то миллионы наблюдений считаются «обычными» данными, а где-то большими называют уже сотни тысяч, потому что у каждого из наблюдений есть тысяча признаков. Поэтому данные решили условно разбить на три части — малые, средние и большие — по самому простому принципу: объему, который они занимают.
Малые данные — это считанные гигабайты. Средние — все, что около терабайта. Одна из основных характеристик больших данных — вес, который составляет примерно петабайт. Но путаницу это не убрало. Поэтому вот критерий еще проще: все, что не помещается на одном сервере — большие данные.
В малых, средних и больших данных разные принципы работы. Большие данные как правило хранятся в кластере сразу на нескольких серверах. Из-за этого даже простые действия выполняются сложнее.
Например, простая задача — найти среднее значение величины. Если это малые данные, мы просто все складываем и делим на количество. А в больших данных мы не можем собрать сразу всю информацию со всех серверов. Это сложно. Зачастую надо не данные тянуть к себе, а отправлять отдельную программу на каждый сервер. После работы этих программ образуются промежуточные результаты, и среднее значение определяется по ним.

Сергей Ширкин


Зачем государству ваши данные?
Как мы уже поняли, корпорации научились использовать данные своих клиентов (и просто разных людей) с собственной выгодой. Учитывая масштабы, речь идет об обезличенных данных, но все равно вопрос безопасности при использования такой информации остается открытым. Но возможность оперировать массивами данных интересует не только частные компании, было логично, что они заинтересуют и государства.
Многие россияне впервые услышали о «больших пользовательских данных» от генерального директора InfoWatch Натальи Касперской. Она в 2020 году заявила, что поисковые запросы, данные о геолокации, контактные данные, сообщения, фото и видео, которые собирают крупные IT-компании вроде Facebook, должны принадлежать государству.
Сделать это она предлагает, законодательно заставив компании передавать сертификаты безопасности правительственным органам или просто переводить все эти данные в Россию (кстати, формально такой закон уже давно существует). И это осталось бы просто частным мнением, но Касперская на тот момент возглавляла подгруппу «Интернет + Общество» в рабочей группе под кураторством помощника президента России.
Аргументация простая – как только пользователь загрузил какие-то свои данные в интернет, они перестают ему принадлежать. А учитывая опыт других стран (например, Китая), было бы логично передавать все эти данные государству. Правда, в дальнейшем об этом ничего не было слышно – либо идея «заглохла», либо ее решили дальше не подвергать огласке.
Что касается Китая
, там действительно есть истории о том, как Facebook согласился сотрудничать с правительством (передавать ему некоторую важную информацию пользователей), а Skype вообще отслеживает «неугодные» слова в сообщениях по определенному справочнику, и цензурирует их.
Последнее, о чем говорили в России в контексте Big Data – это предстоящая перепись населения, в ходе которой обещали использовать наработки по таким технологиям. Кроме прочего, переписчики будут пользоваться планшетными ПК, а данные будут как-то централизованно обрабатываться с использованием технологий Big Data.
Но главное – «большие данные» в России активно используются государственными органами в рамках всем известной «цифровизации».
В частности, эти технологии уже используют в ФНС (которая вообще считается лидером по «цифровизации»), ФСБ, Пенсионном фонде, Фонде ОМС, Следственном комитете и некоторых других органах. Правда, конкретные результаты пока остаются по большей части за кадром – серьезных перемен в медицине не видно, а в налоговой службе все так же часто бывают сбои.
Кроме того, об использовании Big Data и технологий искусственного интеллекта часто говорят в «Сбербанке»
– по словам руководства, это позволило сократить почти всех менеджеров среднего звена, а решения о выдаче кредита теперь часто принимает ИИ. Но снова, для рядовых клиентов «Сбербанк» – это все еще не самый современный банк со странным подходом к клиентам и частыми сбоями.
Какие компании занимаются большими данными
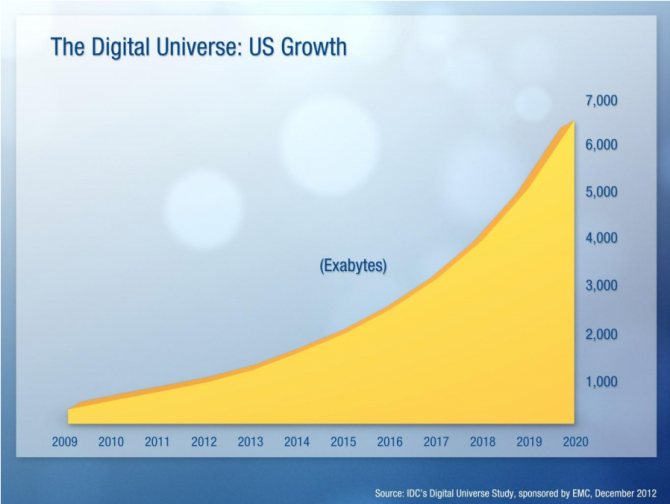
Первыми с большими данными, либо с «биг дата», начали работать сотовые операторы и поисковые системы. У поисковиков становилось все больше и больше запросов, а текст тяжелее, чем цифры. На работу с абзацем текста уходит больше времени, чем с финансовой транзакцией. Пользователь ждет, что поисковик отработает запрос за долю секунды — недопустимо, чтобы он работал даже полминуты. Поэтому поисковики первые начали работать с распараллеливанием при работе с данными.
Чуть позже подключились различные финансовые организации и ритейл. Сами транзакции у них не такие объемные, но большие данные появляются за счет того, что транзакций очень много.
Количество данных растет вообще у всех. Например, у банков и раньше было много данных, но для них не всегда требовались принципы работы, как с большими. Затем банки стали больше работать с данными клиентов. Стали придумывать более гибкие вклады, кредиты, разные тарифы, стали плотнее анализировать транзакции. Для этого уже требовались быстрые способы работы.
Сейчас банки хотят анализировать не только внутреннюю информацию, но и стороннюю. Они хотят получать большие данные от того же ритейла, хотят знать, на что человек тратит деньги. На основе этой информации они пытаются делать коммерческие предложения.
Сейчас вся информация связывается между собой. Ритейлу, банкам, операторам связи и даже поисковикам — всем теперь интересны данные друг друга.
Рынок технологий больших данных в России и мире
По данным на 2014 год 40% объема рынка больших данных составляют сервисные услуги. Немного уступает (38%) данному показателю выручка от использования Big Data в компьютерном оборудовании. Оставшиеся 22% приходятся на долю программного обеспечения.
Наиболее полезные в мировом сегменте продукты для решения проблем Big Data, согласно статистическим данным, – аналитические платформы In-memory и NoSQL . 15 и 12 процентов рынка соответственно занимают аналитическое ПО Log-file и платформы Columnar. А вот Hadoop/MapReduce на практике справляются с проблемами больших данных не слишком эффективно.
Результаты внедрения технологий больших данных:
- рост качества клиентского сервиса;
- оптимизация интеграции в цепи поставок;
- оптимизация планирования организации;
- ускорение взаимодействия с клиентами;
- повышение эффективности обработки запросов клиентов;
- снижение затрат на сервис;
- оптимизация обработки клиентских заявок.
Каким должен быть специалист по большим данным
Поскольку данные расположены на кластере серверов, для их обработки используется более сложная инфраструктура. Это оказывает большую нагрузку на человека, который с ней работает — система должна быть очень надежной.
Сделать надежным один сервер легко. Но когда их несколько — вероятность падения возрастает пропорционально количеству, и так же растет и ответственность дата-инженера, который с этими данными работает.
Аналитик big data должен понимать, что он всегда может получить неполные или даже неправильные данные. Он написал программу, доверился ее результатам, а потом узнал, что из-за падения одного сервера из тысячи часть данных была отключена, и все выводы неверны.
Взять, к примеру, текстовый поиск. Допустим все слова расположены в алфавитном порядке на нескольких серверах (если говорить очень просто и условно). И вот отключился один из них, пропали все слова на букву «К». Поиск перестал выдавать слово «Кино». Следом пропадают все киноновости, и аналитик делает ложный вывод, что людей больше не интересуют кинотеатры.
Поэтому специалист по большим данным должен знать принципы работы от самых нижних уровней — серверов, экосистем, планировщиков задач — до самых верхнеуровневых программ — библиотек машинного обучения, статистического анализа и прочего. Он должен понимать принципы работы железа, компьютерного оборудования и всего, что настроено поверх него.
В остальном нужно знать все то же, что и при работе с малыми данным. Нужна математика, нужно уметь программировать и особенно хорошо знать алгоритмы распределенных вычислений, уметь приложить их к обычным принципам работы с данными и машинного обучения.



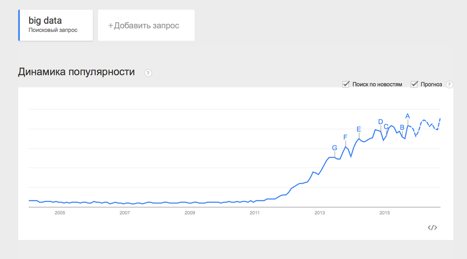
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ.
big data
) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data
я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Какие используются инструменты и технологии big data
Поскольку данные хранятся на кластере, для работы с ними нужна особая инфраструктура. Самая популярная экосистема — это Hadoop. В ней может работать очень много разных систем: специальных библиотек, планировщиков, инструментов для машинного обучения и многого другое. Но в первую очередь эта система нужна, чтобы анализировать большие объемы данных за счет распределенных вычислений.
Например, мы ищем самый популярный твит среди данных разбитых на тысяче серверов. На одном сервере мы бы просто сделали таблицу и все. Здесь мы можем притащить все данные к себе и пересчитать. Но это не правильно, потому что очень долго.
Поэтому есть Hadoop с парадигмами Map Reduce и фреймворком Spark. Вместо того, чтобы тянуть данные к себе, они отправляют к этим данным участки программы. Работа идет параллельно, в тысячу потоков. Потом получается выборка из тысячи серверов на основе которой можно выбрать самый популярный твит.
Map Reduce более старая парадигма, Spark — новее. С его помощью достают данные из кластеров, и в нем же строят модели машинного обучения.





MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce
– это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
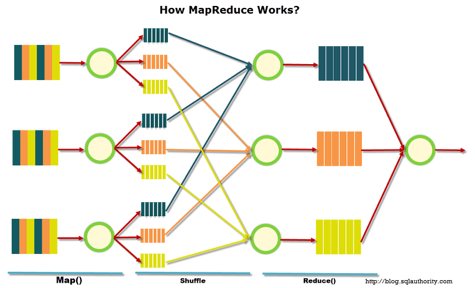
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map
. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение
. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle
. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce
. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины».
Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map
работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce
работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Какие профессии есть в сфере больших данных
Две основные профессии — это аналитики и дата-инженеры.
Аналитик прежде всего работает с информацией. Его интересуют табличные данные, он занимается моделями. В его обязанности входит агрегация, очистка, дополнение и визуализация данных. То есть, аналитик в биг дата — это связующее звено между информацией в сыром виде и бизнесом.
У аналитика есть два основных направления работы. Первое — он может преобразовывать полученную информацию, делать выводы и представлять ее в понятном виде.
Второе — аналитики разрабатывают приложения, которые будет работать и выдавать результат автоматически. Например, делать прогноз по рынку ценных бумаг каждый день.
Дата инженер — это более низкоуровневая специальность. Это человек, который должен обеспечить хранение, обработку и доставку информации аналитику. Но там, где идет поставка и очистка — их обязанности могут пересекаться
Bigdata-инженеру достается вся черная работа. Если отказали системы, или из кластера пропал один из серверов — подключается он. Это очень ответственная и стрессовая работа. Система может отключиться и в выходные, и в нерабочее время, и инженер должен оперативно предпринять меры.
Это две основные профессии, но есть и другие. Они появляются, когда к задачам, связанным с искусственным интеллектом, добавляются алгоритмы параллельных вычислений. Например, NLP-инженер. Это программист, который занимается обработкой естественного языка, особенно в случаях, когда надо не просто найти слова, а уловить смысл текста. Такие инженеры пишут программы для чат-ботов и диалоговых систем, голосовых помощников и автоматизированных колл-центров.
Есть ситуации, когда надо проклассифицировать миллиарды картинок, сделать модерацию, отсеять лишнее и найти похожее. Эти профессии больше пересекаются с компьютерным зрением.
Data Mining — как собирается и обрабатывается Биг Дата
Загрузка больших данных в традиционную реляционную базу для анализа занимает много времени и денег. По этой причине появились специальные подходы для сбора и анализа информации. Для получения и последующего извлечения информацию объединяют и помещают в “озеро данных”. Оттуда программы искусственного интеллекта, используя сложные алгоритмы, ищут повторяющиеся паттерны.
Хранение и обработка происходит следующими инструментами:
- Apache HADOOP — пакетно-ориентированная система обработки данных. Система хранит и отслеживает информацию на нескольких машинах и масштабируется до нескольких тысяч серверов.
- HPPC — платформа с открытым исходным кодом, разработанная LexisNexis Risk Solutions. HPPC известна как суперкомпьютер Data Analytics (DAS), поддерживающая обработку данных как в пакетном режиме, так и в режиме реального времени. Система использует суперкомпьютеры и кластеры из обычных компьютеров.
- Storm — обрабатывает информацию в реальном времени. Использует Eclipse Public License с открытым исходным кодом.
Сколько времени занимает обучение
У нас обучение идет полтора года. Они разбиты на шесть четвертей. В одних идет упор на программирование, в других — на работу с базами данных, в третьих — на математику.
В отличии, например, от факультета ИИ, здесь поменьше математики. Нет такого сильного упора на математический анализ и линейную алгебру. Знания алгоритмов распределенных вычислений нужны больше, чем принципы матанализа.
Но полтора года достаточно для реальной работы с обработкой больших данных только если у человека был опыт работы с обычными данными и вообще в ИТ. Остальным студентам после окончания факультета рекомендуется поработать с малыми и средними данными. Только после этого специалиста могут допустить к работе с большими. После обучения стоит поработать дата-саентистом — поприменять машинное обучение на разных объемах данных.
Когда человек устраивается в большую компанию — даже если у него был опыт — чаще всего его не допустят до больших объемов данных сразу, потому что цена ошибки там намного выше. Ошибки в алгоритмах могут обнаружиться не сразу, и это приведет к большим потерям.
Методики анализа и обработки

К основным способам анализа больших массивов информации относят следующие:
- Глубинный анализ, классификация данных. Эти методики пришли из технологий работы с обычной структурированной информацией в небольших массивах. Однако в новых условиях используются усовершенствованные математические алгоритмы, основанные на достижениях в цифровой сфере.
- Краудсорсинг. В основе этой технологии возможность получать и обрабатывать потоки в миллиарды байт из множества источников. Конечное число «поставщиков» не ограничивается ничем. Разве только мощностью системы.
- Сплит-тестирование. Из массива выбираются несколько элементов, которые сравниваются между собой поочередно «до» и «после» изменения. АВ тесты помогают определить, какие факторы оказывают наибольшее влияние на элементы. Например, с помощью сплит-тестирования можно провести огромное количество итераций постепенно приближаясь к достоверному результату.
- Прогнозирование. Аналитики стараются заранее задать системе те или иные параметры и в дальнейшей проверять поведение объекта на основе поступления больших массивов информации.
- Машинное обучение. Искусственный интеллект в перспективе способен поглощать и обрабатывать большие объемы несистематизированных данных, впоследствии используя их для самостоятельного обучения.
- Анализ сетевой активности. Методики big data используются для исследования соцсетей, взаимоотношений между владельцами аккаунтов, групп, сообществами. На основе этого создаются целевые аудитории по интересам, геолокации, возрасту и прочим метрикам.
Как готовиться к собеседованиям
Не нужно углубляться только в один предмет. На собеседованиях задают вопросы по статистике, по машинному обучению, программированию. Могут спросить про структуры больших данных, алгоритмы, применение, технологии, про кейсы из реальной жизни: упали сервера, случилась авария — как устранять? Могут быть вопросы по предметной сфере — то, что ближе к бизнесу
И если человек слишком углубился в одну математику, и на собеседовании не сделал простое задание по программированию, то шансы на трудоустройство снижаются. Лучше иметь средний уровень по каждому направлению, чем показать себя хорошо в одном, а в другом провалиться полностью.
Есть список вопросов, которые задают на 80 процентах собеседований. Если это машинное обучение — обязательно спросят про градиентный спуск. Если статистика — нужно будет рассказать про корреляцию и проверку гипотез. По программированию скорее всего дадут небольшую задачу средней сложности. А на задачах можно легко набить руку — просто побольше их решать.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение
:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
| def map(doc): for word in doc: yield word, 1 | def reduce(word, values): yield word, sum(values) |
Функция map
превращает входной документ в набор пар (слово, 1),
shuffle
прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]),
reduce
суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача
: имеется csv-лог рекламной системы вида:
,,,,, 11111,RU,Moscow,2,4,0.3 22222,RU,Voronezh,2,3,0.2 13413,UA,Kiev,4,11,0.7 … Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Решение:
| def map(record): user_id, country, city, campaign_id, creative_id, payment = record.split(«,») payment=float(payment) if country == «RU»: yield city, payment |
| def reduce(city, payments): yield city, sum(payments)/len(payments) |
Функция map
проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция
reduce
вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Где набираться опыта самостоятельно
Python можно подтянуть на Питонтьютор, работы с базой данных — на SQL-EX. Там даются задачи, по которым на практике учатся делать запросы.
Высшая математика — Mathprofi. Там можно получить понятную информацию по математическому анализу, статистике и линейной алгебре. А если плохо со школьной программой, то есть сайт youclever.org
Распределенные же вычисления тренировать получится только на практике. Во-первых для этого нужна инфраструктура, во-вторых алгоритмы могут быстро устаревать. Сейчас постоянно появляется что-то новое.
Перспективы развития
В 2020 году важность понимания и главное работы с массивами информации возросла в 4-5 раз по сравнению с началом десятилетия. С массовостью пришла интеграция big data в сферы малого и среднего бизнеса, стартапы:
- Облачные хранилища. Технологии хранения и работы с данными в онлайн-пространстве позволяет решить массу проблем малого и среднего бизнеса: дешевле купить облако, чем содержать дата-центр, персонал может работать удаленно, не нужен офис.
- Глубокое обучение, искусственный интеллект. Аналитические машины имитируют человеческий мозг, то есть используются искусственные нейронные сети. Обучение происходит самостоятельно на основе больших массивов информации.
- Dark Data – сбор и хранение не оцифрованных данных о компании, которые не имеют значимой роли для развития бизнеса, однако они нужны в техническом и законодательном планах.
- Блокчейн. Упрощение интернет-транзакций, снижение затрат на проведение этих операций.
- Системы самообслуживания – с 2020 года внедряются специальные платформы для малого и среднего бизнеса, где можно самостоятельно хранить и систематизировать данные.
Какие тренды обсуждает сообщество
Постепенно набирает силу еще одно направление, которое может привести к бурному росту количества данных — Интернет вещей (IoT). Большие данные такого рода поступают с датчиков устройств, объединенных в сеть, причем количество датчиков в начале следующего десятилетия должно достигнуть десятков миллиардов.
Устройства самые разные — от бытовых приборов до транспортных средств и промышленных станков, непрерывный поток информации от которых потребует дополнительной инфраструктуры и большого числа высококвалифицированных специалистов. Это означает, что в ближайшее время возникнет острый дефицит дата инженеров и аналитиков больших данных.
Блокчейн подходит не для всех бизнес-задач
«Блокчейн был разработан для решения узкого набора проблем, где требуется децентрализация и неизменяемость. Эти параметры технологии сужают круг задач, для которых его можно использовать», – объясняет Джулиан Эрес, эксперт в области BI и анализа данных.
Недавний отчёт Международного экономического форума также советует с осторожностью относиться к блокчейну. Авторы отчёта: Кэти Маллиган, ДжП Гуруджи, Шейла Уоррен и Дженнифер Чжу Скотт. Они объясняют: «Руководители компании не должны соблазняться хайпом. Вместо этого они обязаны честно ответить себе на вопрос: будет ли блокчейн здравым бизнес-решением несмотря на ясно очерченные проблемы».
По мнению авторов отчёта, те, кто рассматривает для себя применение блокчейна, должны понять бизнес-контекст, в котором оно планируется. По сути необходимо задать себе один вопрос: «Нужно ли для решения конкретной бизнес-проблемы устранить посредника?».
«Может быть дешевле без посредника сотрудничать с поставщиками, чем работать через расчётно-клиринговую компанию. Так, блокчейн-платформа CORDA в банковской индустрии для управления денежными переводами позволяет предоставлять услуги быстрее, безопаснее и дешевле. То же касается устранения любых других посредников: технологического брокера или страхового агента».
Криптовалюта Биткойн
Такой подход дает одно из самых больших преимуществ технологии, поскольку манипулирование данными становится сравнительно маловероятным. Если пользователь изменяет сохраненную информацию, все остальные пользователи могут распознать мошенничество. Сравнивая разные версии блокчейна, можно в кратчайшие сроки выявить мошенников и запретить им доступ в сеть. В техническом документе Биткойн такой подход рассматривается как способ предотвращения несанкционированного использования доступного капитала. Это предлагает пользователю очень высокий уровень безопасности. В целом, технология блокчейн ориентирована на безопасность, прозрачность, анонимность и децентрализацию.
Каковы преимущества и недостатки технологии блокчейн?
Теперь, когда принцип блокчейна был прояснен, мы можем подробнее рассмотреть преимущества и недостатки этой технологии:
Преимущества блокчейн
В принципе, хранимые данные анонимны и зашифрованы, что позволяет использовать блокчейн во многих областях.Доступ к сохраненным данным возможен только при использовании правильного ключа.Если в компании используется блокчейн, можно также собирать и анализировать большие объемы данных.Привлекая разных пользователей, собранные данные можно проверять особенно быстро и надежно.Поскольку все транзакции процесса хранятся в цепочке блоков, их также можно отследить впоследствии. Эта процедура обеспечивает особенно высокую степень прозрачности, например, в контексте анализа ошибок.Если блокчейн используется в сфере платежных транзакций, это может помочь снизить затраты.Это также позволяет оптимизировать отчетность о транзакциях.
Однако, помимо этих преимуществ, использование технологии блокчейн также имеет некоторые недостатки:Пока эта технология еще не получила широкого распространения, поэтому в настоящее время существует лишь несколько полных решений. Внедрение требует усилий и экспертных знаний, что в настоящее время редко.Скорость транзакций этой технологии в настоящее время очень низкая. Задержка транзакций в блокчейне Биткойн, в частности, в прошлом давала понять, что валюта не подходит для традиционных платежных транзакций.Кроме того, существуют проблемы с пространством для хранения, потому что цепочка блоков постоянно растет с новыми транзакциями и требует больше места для хранения.